
Lambdaless microservices connect API Gateway directly to data repositories such as DynamoDB, without Lambda functions in between. The result can help reduce complexity and maintenance effort.
A typical serverless use case is building JSON APIs. You have probably seen diagrams similar to this:
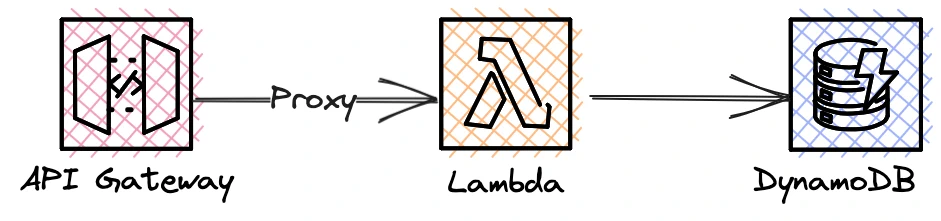
Compared to EC2-based deployments, the serverless architecture brings a few advantages. AWS cares of runtime and operating system updates, makes fundamental scaling decisions for you and you pay per request, but never for over-provisioning. You can deploy your application without worrying about networking basics like subnets, security groups and routing tables.
While this approach reduces engineering overhead, there is one thing that doesn’t change: Both EC2 and serverless solutions require application code to glue API Gateway and DynamoDB together. Both require you to size CPU and memory sufficiently and eventually care of major runtime version upgrades. Is there an option to further reduce that maintenance effort?
Lambdaless JSON API
Let’s say your Lambda function does not contain sophisticated business logic, but only creates, reads, updates and deletes DynamoDB items. Essentially, it validates and authorizes requests and eventually communicates with DynamoDB. If you think this might change in the future, note that the following approach can easily be converted to serverless at a later date, should it ever become necessary.
Let’s eliminate the “Lambda glue” and connect API Gateway directly with DynamoDB.

In the API Gateway console, it looks like this:
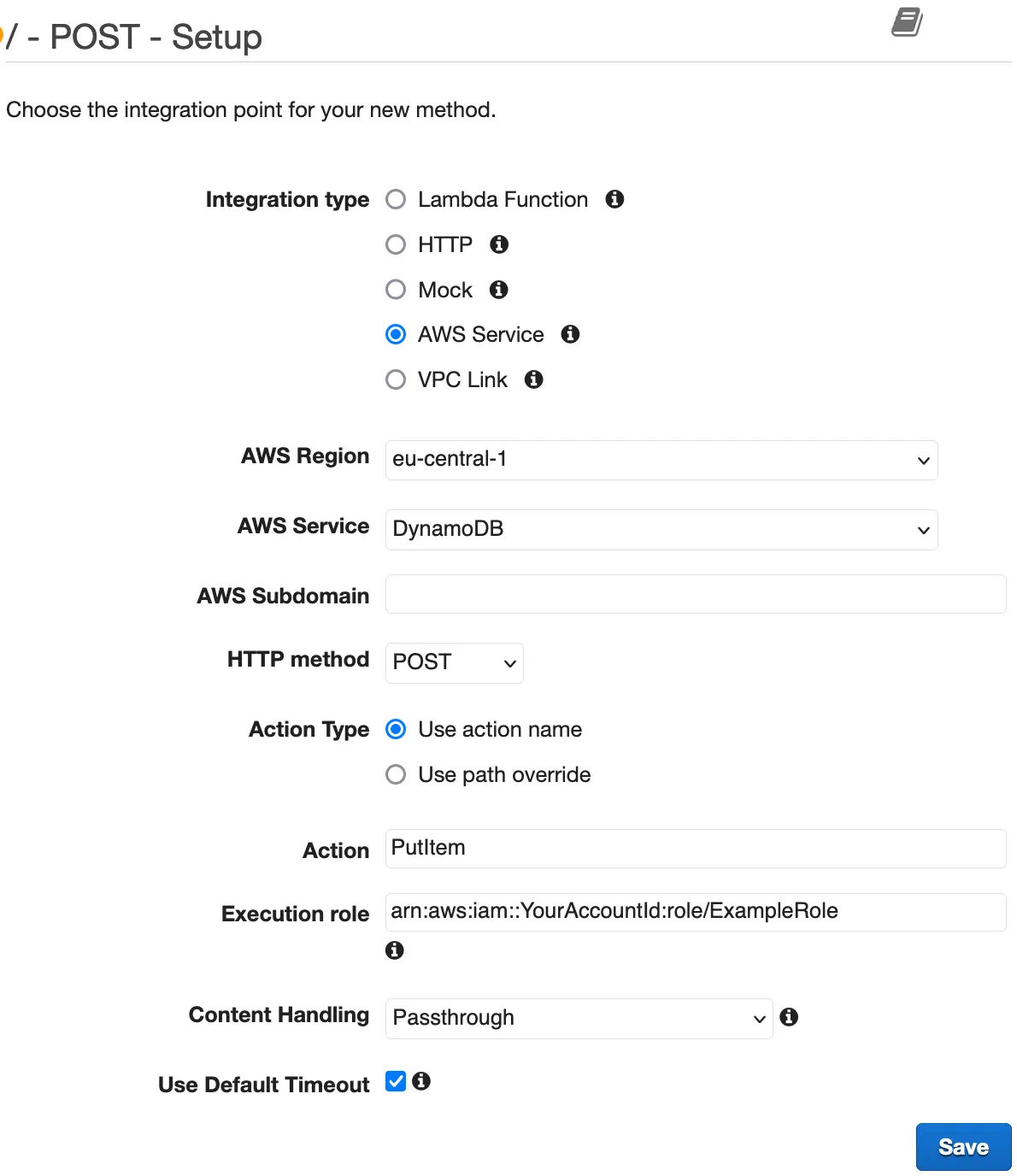
PutItem action, which requires a POST request.
Make sure you select an execution role
that allows API Gateway to perform the PutItem action on the respective table resource.Besides DynamoDB, you can connect API Gateway in REST mode to Amazon Simple Notification Service (SNS), Simple Queue Service (SQS), StepFunctions, and more. For instance, if your use case is to collect clickstream data for a huge news website, API Gateway and Kinesis make a great duo.
At the time of writing this article, API Gateway in HTTP mode (also known as API Gateway v2) works similarly, but connects to a subset of services.
Request validation
If your Lambda function handled request payload validation, you have to migrate your validation code to JSON schema. API Gateway natively supports request schema validation using JSON schema draft 4. This is especially recommended in order to avoid unexpected amounts of data in DynamoDB.
Your first model might look like this:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "CreateItemModel",
"type": "object",
"required": [
"data"
],
"properties": {
"data": {
"type": "string",
"maxLength": 128
}
}
}
Request transformation
After you ensured the request payload is valid,
you finally have to transform the data into the regular DynamoDB API format.
In API Gateway, create a request mapping template for the content-type application/json and map your input values with the expected DynamoDB fields.
You can use Velocity Template Language (VTL) scripts inside your mapping templates.
PutItem
For the PutItem API, it might look like this:
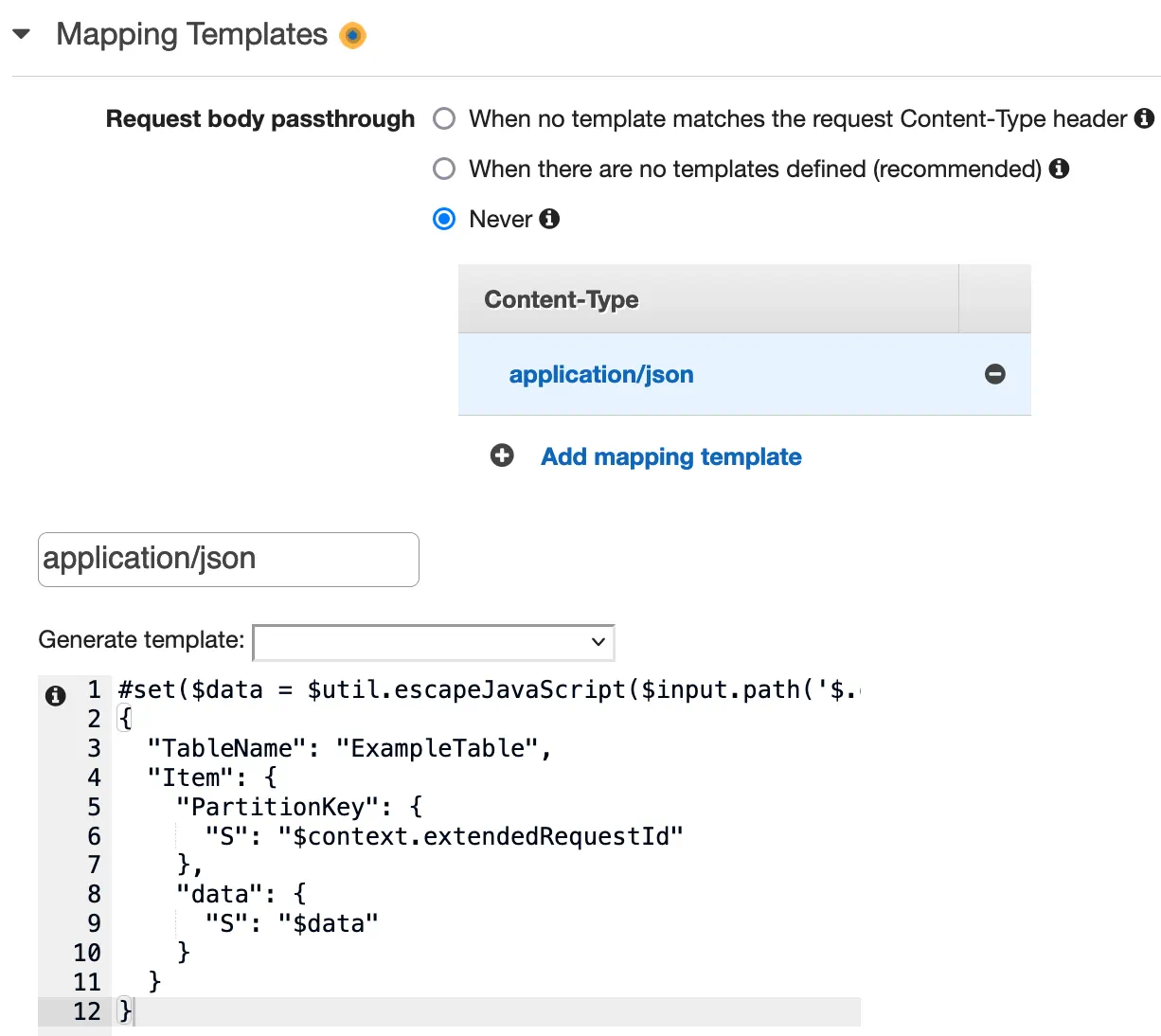
application/json.
Make sure you select “Request body passthrough: Never” to avoid unexpected requests to DynamoDB.#set($data = $util.escapeJavaScript($input.path('$.data')))
{
"TableName": "ExampleTable",
"Item": {
"PartitionKey": {
"S": "$context.extendedRequestId"
},
"data": {
"S": "$data"
}
}
}
If you’re looking for a random partition key, note that clients can override $context.requestId.
You might choose $context.extendedRequestId instead.
GetItem
Your request mapping template for the GetItem action might look like this:
{
"TableName": "ExampleTable",
"Key": {
"PartitionKey": {
"S": "$input.params('id')"
}
}
}
This way you can also implement UpdateItem, DeleteItem, and whatever else you need. Always make sure that your input data is validated and properly sanitized.
Response transformation
If you want to delight your API consumers with developer-friendly payloads, you can apply the same mapping template logic for the response.
#set($data = $util.escapeJavaScript($input.path('$.Item.data.S')))
{
"id": "$input.path('$.Item.PartitionKey.S')",
"data": "$data"
}
Authorization
API Gateway gives you a variety of options to authorize your requests.
If you’re already using an identity provider which complies with the SAML or OpenID Connect specification, the Cognito user pool integration might be a good choice. However, if your API consumers are able to use IAM-based authentication, the built-in IAM authorizer allows you to leverage existing entities like IAM users and roles. This is particularly convenient for server-to-server communication, or in combination with AWS IAM Identity Center (formerly known as AWS SSO).
My personal experience
A popular news website asked me to build a recommendation system based on clickstream data. The ultimate goal was to get results in near real time but no later than when a user finished reading an article.
I chose a lambdaless architecture using API Gateway and Kinesis Data Streams on the data ingest side. Compared to serverless, the lack of a glue function reduced the processing latency by 21 ms (p95) per request and the monthly costs by 10 %. In addition, there are long-term savings with this maintenance-free API.
Conclusion
Use cases: Lambdaless microservices are a convenient solution for use cases that get along with API Gateway’s built-in schema validation options and authorization mechanisms. Use cases that don’t require sophisticated business logic or data transformations. Because there is no runtime that needs to be chosen, maintained and updated, the long-term maintenance effort is comparatively low. Lambdaless microservices can easily be converted to serverless microservices at a later date.
Costs: You save the Lambda execution fees unless you choose to use a Lambda authorizer. For simple CRUD operations that don’t deal with large amounts of data, the savings with Lambda are probably negligible. I recommend doing a quick cost estimate using the AWS Pricing Calculator.
Resilience: The default Lambda concurrent execution quota per region is 1,000 (sometimes lower for newly created AWS accounts). Eliminating the “Lambda glue” makes your application resilient to Lambda quota limitations. If you’re not sure how Lambda will scale under a heavy load, and you don’t want to spend time on optimizing Lambda for that case, adopting a lambdaless architecture might be a significant option.
Maintenance effort: Other than the schema validations and mapping templates, this is a no-code solution. One less component to operate and monitor.
Tools: You will need additional tools if you want to unit test your schema validation and mapping templates.
Further considerations
How do you troubleshoot a lambdaless microservice?
The answer is: The same way you would troubleshoot a serverless microservice. AWS X-Ray integrates perfectly with this solution. In addition to API Gateway logs, the API Gateway test feature exposes latencies and DynamoDB integration requests and responses.
Request Schema Validation Unit Testing
Request schemas are JSON schema draft 4 documents. Consider using third-party JSON schema implementations that support draft 4. Inject your request schema and verify it with test data. It will probably be close to the AWS implementation.
Mapping Template Unit Testing
Request mapping templates use the Velocity Template Langauge (VTL). There are a few public VTL implementations that can be used with your test data to see if your templates work as expected. Since mapping templates also contain JSON paths, you probably have to implement some additional tooling. Perhaps something to give back to the open source community?
{kind=link}